🧪 少样本提示
同样在推理场景,我们提到了少样本提示(Few-Shot Prompting)的技术,本章介绍下它的优缺点和技巧。
介绍
我们在技巧 2 中,提到了可以给模型一些示例,从而让模型返回更符合我们需求的答案。这个技巧其实使用的就是少样本提示的方法。
这个方法最早是 Brown 等人在 2020 年发现的,论文里有一个这样的例子,非常有意思,通过这个例子你应该更能体会,像 ChatGPT 这类统计语言模型,其实并不懂意思,只是懂概率 😁。
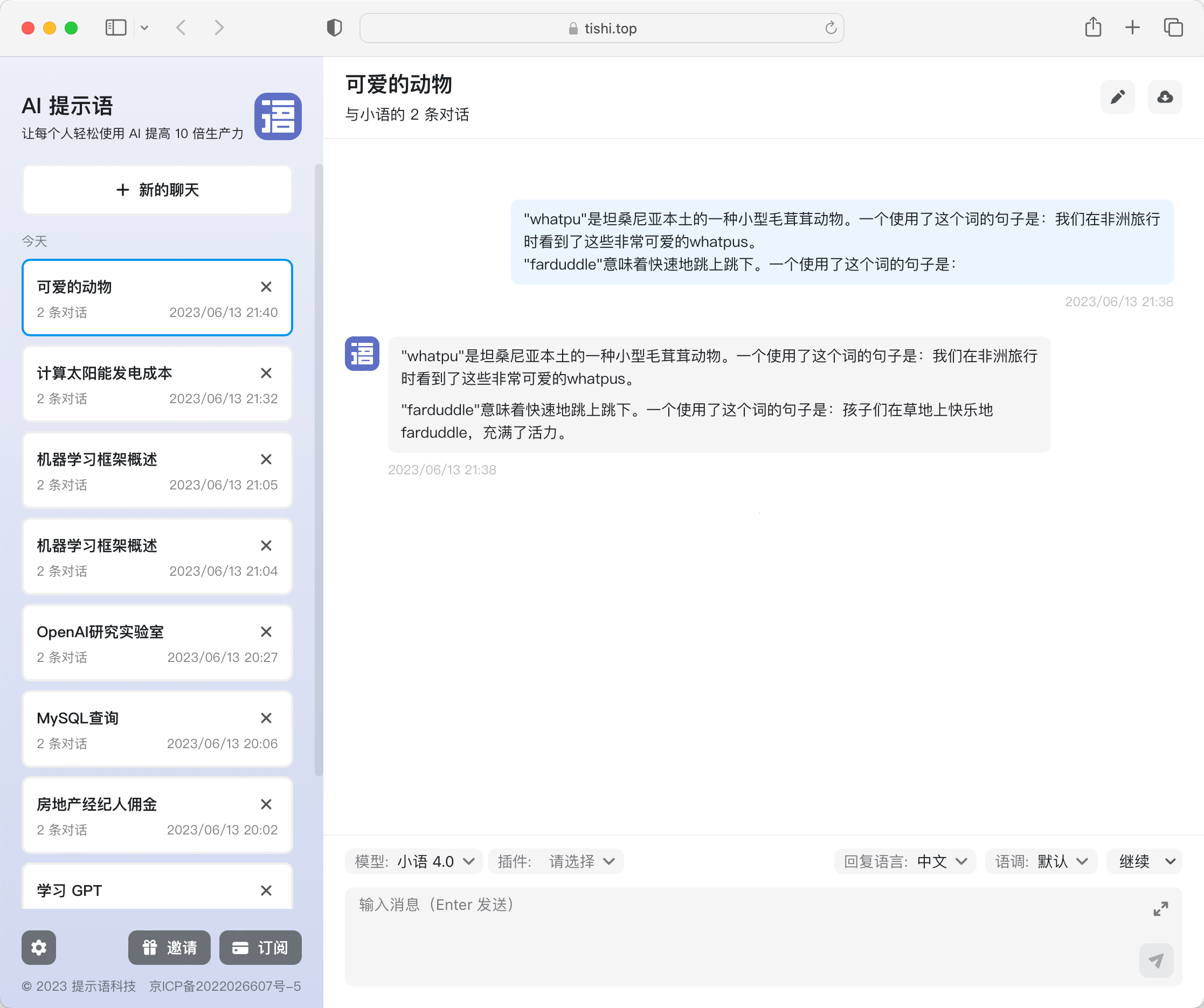
Brown 输入的内容是这样的(whatpu 和 farduddle 其实根本不存在):
"whatpu"是坦桑尼亚本土的一种小型毛茸茸动物。一个使用了这个词的句子是:我们在非洲旅行时看到了这些非常可爱的whatpus。
"farduddle"意味着快速地跳上跳下。一个使用了这个词的句子是:
回复是这样的:
孩子们在草地上快乐地farduddle,充满了活力。
小语GPT计算概率问题
不过这并不代表,少样本提示就没有缺陷,我们试试下面这个例子:
提示语:
这组数中的奇数之和为偶数:4, 8, 9, 15, 12, 2, 1。
答案:错误。
这组数中的奇数之和为偶数:17, 10, 19, 4, 8, 12, 24。
答案:正确。
这组数中的奇数之和为偶数:16, 11, 14, 4, 8, 13, 24。
答案:正确。
这组数中的奇数之和为偶数:17, 9, 10, 12, 13, 4, 2。
答案:错误。
这组数中的奇数之和为偶数:15, 32, 5, 13, 82, 7, 1。
答案:
答案是这样的:
答案:正确。
输出的答案其实是错误的,实际上的答案应该是:
将所有奇数(15、5、13、7、1)相加得到41。答案是错误的。
那我们有没有什么方法解决?
技巧8:少样本思维链
要解决这个缺陷,就要使用到新的技巧「少样本思维链」。
根据 Wei 他们团队在 2022 年的研究表明:
通过向大语言模型展示一些少量的样例,并在样例中解释推理过程,大语言模型在回答提示时也会显示推理过程。这种推理的解释往往会引导出更准确的结果。
下面是论文里的案例,使用方法很简单,在技巧2 的基础上,再将逻辑过程告知给模型即可。从下面这个案例里,你可以看到加入解释后,输出的结果就正确了。

.png)
少样本思维链提示语 VS 标准提示语对比图
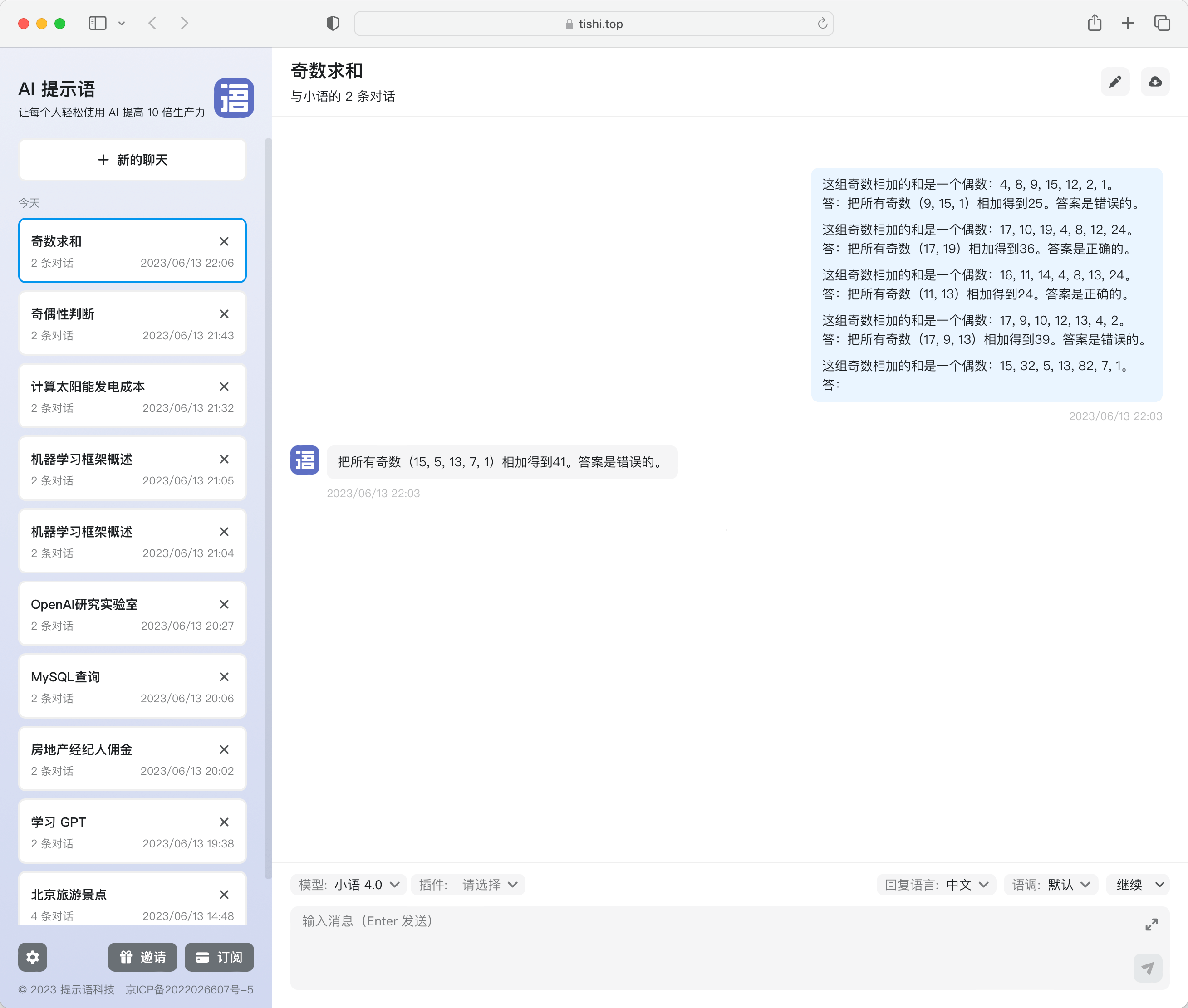
那本章开头提的例子就应该是这样的(注:本例子同样来自 Wei 团队论文):
这组奇数相加的和是一个偶数:4, 8, 9, 15, 12, 2, 1。
答:把所有奇数(9, 15, 1)相加得到25。答案是错误的。
这组奇数相加的和是一个偶数:17, 10, 19, 4, 8, 12, 24。
答:把所有奇数(17, 19)相加得到36。答案是正确的。
这组奇数相加的和是一个偶数:16, 11, 14, 4, 8, 13, 24。
答:把所有奇数(11, 13)相加得到24。答案是正确的。
这组奇数相加的和是一个偶数:17, 9, 10, 12, 13, 4, 2。
答:把所有奇数(17, 9, 13)相加得到39。答案是错误的。
这组奇数相加的和是一个偶数:15, 32, 5, 13, 82, 7, 1。
答:
小语GPT通过少样本策略计算概率问题示例
聊完技巧,我们再结合前面的零样本思维链,来聊聊思维链的关键知识。根据 Sewon Min 等人在 2022 年的研究 表明,思维链有以下特点:
- 标签空间和输入文本的分布都是关键因素(无论这些标签是否正确)。
- 即使只是使用随机标签,使用适当的格式也能提高性能。
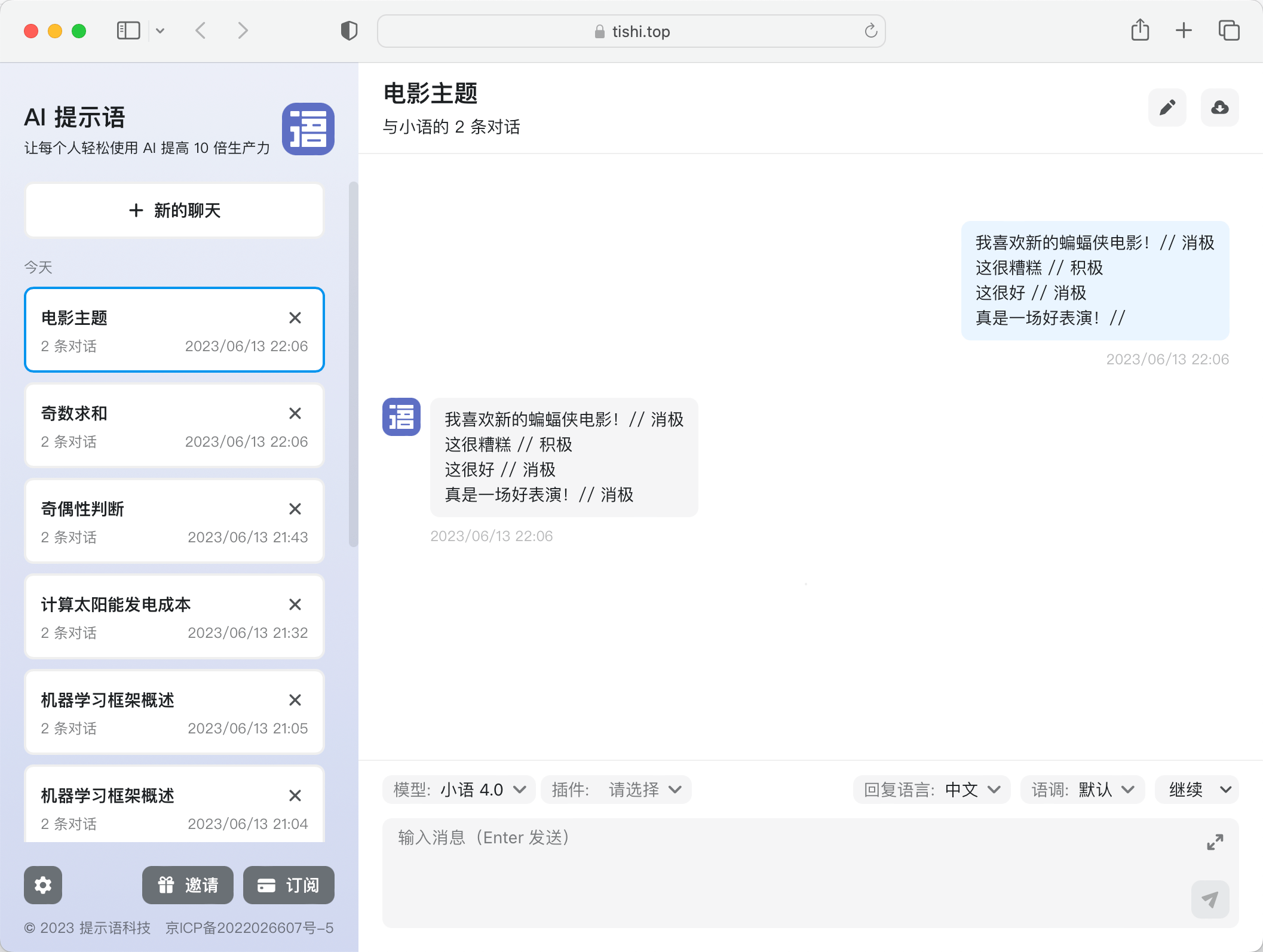
理解起来有点难,我们找一个提示语案例给大家解释。我们给小语 GPT 一些不一定准确的例子:
我喜欢新的蝙蝠侠电影!// 消极
这很糟糕 // 积极
这很好 // 消极
真是一场好表演!//
回复是这样的:
消极
小语GPT通过少样本策略计算概率问题示例
在上述的案例里,每一行我们都写了一句话和一个情感词,并用 // 分开,但我给这些句子都标记了错误的答案,比如第一句其实应该是积极才对。但:
- 即使我们给内容打的标签是错误的(比如第一句话,其实应该是积极),对于模型来说它仍然会知道需要输出什么东西。 换句话说,模型知道 // 划线后要输出一个衡量该句子表达何种感情的词(积极或者消极)。即使我们给的标签是错误的,或者换句话说,是否基于事实并不重要。标签和输入的文本以及格式才是关键因素。
- 只要给了示例,即使随机的标签,对于模型生成结果来说都是有帮助的。